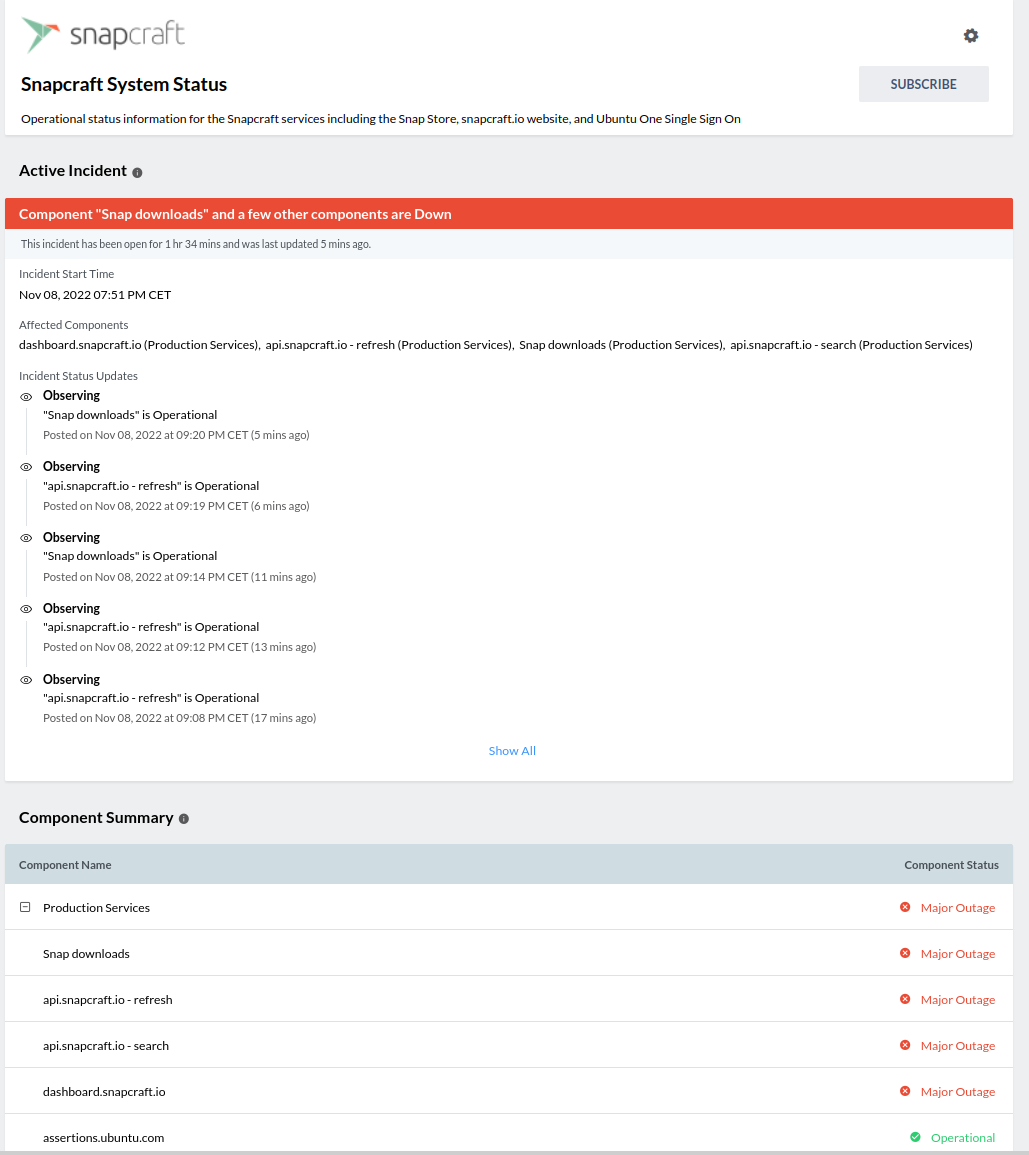
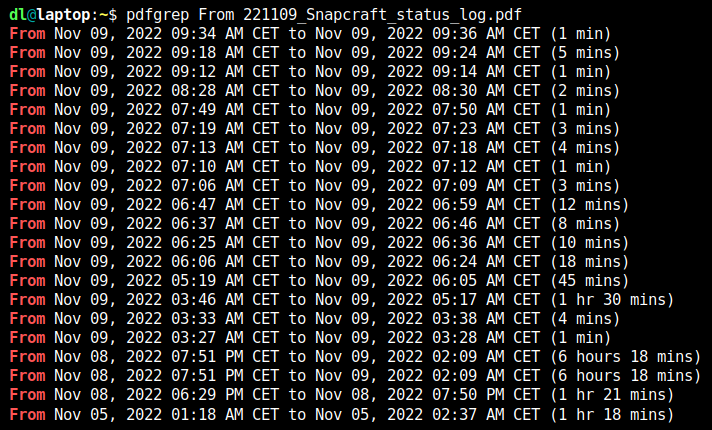
Apparently somebody managed to resell Seagate hard disks that have 2-5 years of operations on them as brand new.
They did this by using some new shrink wrap bags and resetting the used hard disk SMART attributes to factory-new values.

Luckily Seagate has a proprietary extension "Seagate FARM (Field Access Reliability Metrics)" implemented in their disks that ... the crooks did not reset.
Luckily ... because other manufacturers do not have that extension. And you think the crooks only re-sell used Seagate disks? Lol.
To get access to the Seagate FARM extension, you need smartctl from smartmontools v7.4 or later.
For Debian 12 (Bookworm) you can add the backports archive and then install with
apt install smartmontools/bookworm-backports.
For Debian 11 (Bullseye) you can use a backport we created at my company:
You can also download static builds from https://builds.smartmontools.org/ which keeps the latest CI builds of the current development branch (v7.5 at the time of writing).
To check the state of your drives, compare the output from smartctl -x and smartctl -l farm. Double checking Power_On_Hours vs. "Power on Hours" is the obvious. But the other values around "Head Flight Hours" and "Power Cycle Count" should also roughly match what you expect from a hard disk of a certain age. All near zero, of course, for a factory-new hard disk.
This is what it looks like for a hard disk that has gracefully serviced 4 years and 8 months so far. The smartctl -x and smartctl -l farm data match within some small margins:
$ smartctl -x /dev/sda
smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.1.0-30-amd64] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate Exos X14
Device Model: ST10000NM0568-2H5110
[..]
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
[..]
4 Start_Stop_Count -O--CK 100 100 020 - 26
[..]
9 Power_On_Hours -O--CK 054 054 000 - 40860
10 Spin_Retry_Count PO--C- 100 100 097 - 0
12 Power_Cycle_Count -O--CK 100 100 020 - 27
[..]
192 Power-Off_Retract_Count -O--CK 100 100 000 - 708
193 Load_Cycle_Count -O--CK 064 064 000 - 72077
[..]
240 Head_Flying_Hours ------ 100 253 000 - 21125h+51m+45.748s
$ smartctl -l farm /dev/sda
smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.1.0-30-amd64] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
Seagate Field Access Reliability Metrics log (FARM) (GP Log 0xa6)
FARM Log Page 0: Log Header
FARM Log Version: 2.9
Pages Supported: 6
Log Size: 98304
Page Size: 16384
Heads Supported: 24
Number of Copies: 0
Reason for Frame Capture: 0
FARM Log Page 1: Drive Information
[..]
Power on Hours: 40860
Spindle Power on Hours: 34063
Head Flight Hours: 24513
Head Load Events: 72077
Power Cycle Count: 28
Hardware Reset Count: 193
You may like to run the command below on your systems to capture the state. Remember FARM is only supported on Seagate drives.
for i in /dev/sd{a,b,c,d,e,f,g,h} ; do { smartctl -x $i ; smartctl -l farm $i ; } >> $(date +'%y%m%d')_smartctl_$(basename $i).txt ; done


 NB: The context menu allows to switch the fonts on systems where the above snippet has not (yet) been installed. So good enough for a one-off.
NB: The context menu allows to switch the fonts on systems where the above snippet has not (yet) been installed. So good enough for a one-off. .
.





")