
So, your machine now needs minutes to boot before you can ssh in where it used to be seconds before the Debian Buster update?
Problem
Linux 3.17 (2014-10-05) learnt a new syscall getrandom() that, well, gets bytes from the entropy pool.
Glibc learnt about this with 2.25 (2017-02-05) and two tries and four years after the kernel, OpenSSL used that functionality from release 1.1.1 (2018-09-11).
OpenSSH implemented this natively for the 7.8 release (2018-08-24) as well.
Now the getrandom() syscall will block1 if the kernel can't provide enough entropy. And that's frequenty the case during boot. Esp. with VMs that have no input devices or IO jitter to source the pseudo random number generator from.
First seen in the wild January 2017
I vividly remember not seeing my Alpine Linux VMs back on the net after the Alpine 3.5 upgrade. That was basically the same issue.
Systemd. Yeah.
Systemd makes this behaviour worse, see issues #4271, #4513 and #10621.
Basically as of now the entropy file saved as /var/lib/systemd/random-seed will not - drumroll - add entropy to the random pool when played back during boot. Actually it will. It will just not be accounted for. So Linux doesn't know. And continues blocking getrandom(). This is obviously different from SysVinit times2 when /var/lib/urandom/random-seed (that you still have lying around on updated systems) made sure the system carried enough entropy over reboot to continue working right after enough of the system was booted.
#4167 is a re-opened discussion about systemd eating randomness early at boot (hashmaps in PID 0...). Some Debian folks participate in the recent discussion and it is worth reading if you want to learn about the mess that booting a Linux system has become.
While we're talking systemd ... #10676 also means systems will use RDRAND in the future despite Ted Ts'o's warning on RDRAND [Archive.org mirror and mirrored locally as 130905_Ted_Tso_on_RDRAND.pdf, 205kB as Google+ will be discontinued in April 2019].
Update: RDRAND doesn't return random data on pre-Ryzen AMD CPUs (AMD CPU family <23) as per systemd bug #11810. It will always be 0xFFFFFFFFFFFFFFFF (264-1). This is a known issue since 2014, see kernel bug #85991.
Debian
Debian is seeing the same issue working up towards the Buster release, e.g. Bug #912087.
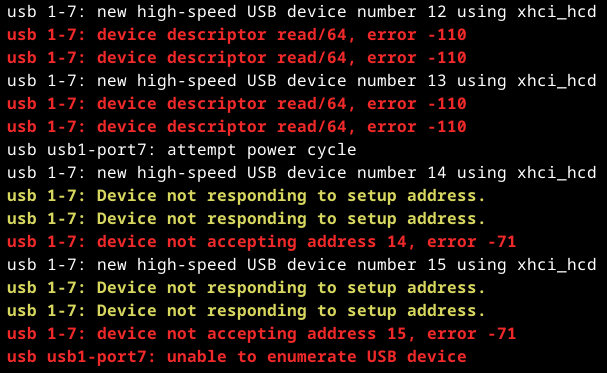
The typical issue is:
[ 4.428797] EXT4-fs (vda1): mounted filesystem with ordered data mode. Opts: data=ordered
[ 130.970863] random: crng init done
with delays up to tens of minutes on systems with very little external random sources.
This is what it should look like:
[ 1.616819] random: fast init done
[ 2.299314] random: crng init done
Check dmesg | grep -E "(rng|random)" to see how your systems are doing.
If this is not fully solved before the Buster release, I hope some of the below can end up in the release notes3.
Solutions
You need to get entropy into the random pool earlier at boot. There are many ways to achieve this and - currently - all require action by the system administrator.
Kernel boot parameter
From kernel 4.19 (Debian Buster currently runs 4.18 [Update: but will be getting 4.19 before release according to Ben via Mika]) you can set RANDOM_TRUST_CPU at compile time or random.trust_cpu=on on the kernel command line. This will make recent Intel / AMD systems trust RDRAND and fill the entropy pool with it. See the warning from Ted Ts'o linked above.
Update: Since Linux kernel build 4.19.20-1 CONFIG_RANDOM_TRUST_CPU has been enabled by default in Debian.
Using a TPM
The Trusted Platform Module has an embedded random number generator that can be used. Of course you need to have one on your board for this to be useful. It's a hardware device.
Load the tpm-rng module (ideally from initrd) or compile it into the kernel (config HW_RANDOM_TPM).
Now, the kernel does not "trust" the TPM RNG by default, so you need to add
rng_core.default_quality=1000
to the kernel command line.
1000 means "trust", 0 means "don't use". So you can chose any value in between that works for you depending on how much you consider your TPM to be unbugged.
VirtIO (KVM, QEMU, ...)
For Virtual Machines (VMs) you can forward entropy from the host (that should be running longer than the VMs and have enough entropy) via virtio_rng.
So on the host, you do:
kvm ... -object rng-random,filename=/dev/urandom,id=rng0 -device virtio-rng-pci,rng=rng0,bus=pci.0,addr=0x7
and within the VM newer kernels should automatically load virtio_rng and use that.
You can confirm with dmesg as per above.
Or check:
# cat /sys/devices/virtual/misc/hw_random/rng_available
virtio_rng.0
# cat /sys/devices/virtual/misc/hw_random/rng_current
virtio_rng.0
Patching systemd
The Fedora bugtracker has a bash / python script that replaces the systemd rnd seeding with a (better) working one. The script can also serve as a good starting point if you need to script your own solution, e.g. for reading from an entropy provider available within your (secure) network.
Chaoskey
The wonderful Keith Packard and Bdale Garbee have developed a USB dongle, ChaosKey, that supplies entropy to the kernel. Hard- and software are open source.
Jitterentropy_RNG
Kernel 4.2 introduced jitterentropy_rng which will use the jitter in CPU timings to generate randomness.
modprobe jitterentropy_rng
This apparently needs a userspace daemon though (read: design mistake) so
apt install jitterentropy-rngd (available from Buster/testing).
The current version 1.0.8-3 installs nicely on Stretch. dpkg -i is your friend.
But - drumroll - that daemon doesn't seem to use the kernel module at all.
That's where I stopped looking at that solution. At least for now. There are extensive docs if you want to dig into this yourself.
Update: The Linux kernel 5.3 will have an updated jitterentropy_rng as per Commit 4d2fa8b44. This is based on the upstream version 2.1.2 and should be worth another look.
Haveged
apt install haveged
Haveged is a user-space daemon that gathers entropy though the timing jitter any CPU has. It will only run "late" in boot but may still get your openssh back online within seconds and not minutes.
It is also - to the best of my knowledge - not verified at all regarding the quality of randomness it generates.
The haveged design and history page provides and interesting read and I wouldn't recommend haveged if you have alternatives. If you have none, haveged is a wonderful solution though as it works reliably. And unverified entropy is better than no entropy. Just forget this is 2018 2019  .
.
early-rng-init-tools
Thorsten Glaser has posted newly developed early-rng-init-tools in a debian-devel thread. He provides packages at http://fish.mirbsd.org/~tg/Debs/dists/sid/wtf/Pkgs/early-rng-init-tools/ .
First he deserves kudos for naming a tool for what it does. This makes it much more easily discoverable than the trend to name things after girlfriends, pets or anime characters. The implementation hooks into the early boot via initrd integration and carries over a seed generated during the previous shutdown. This and some other implementation details are not ideal and there has been quite extensive scrutiny but none that discovered serious issues. Early-rng-init-tools look like a good option for non-RDRAND (~CONFIG_RANDOM_TRUST_CPU) capable platforms.
Linus to the rescue
Luckily end of September Linus Torvalds was fed up with the entropy starvation issue and the non-conclusive discussions about (mostly) who's at fault and ... started coding.
With the kernel 5.4 release on 25.11.2019 his patch has made it into mainline. He created a try_to_generate_entropy function that uses CPU jitter to generate seed entropy for the PRNG early in boot.
In the merge commit Linus explains:
This is admittedly partly "for discussion". We need to have a way
forward for the boot time deadlocks where user space ends up waiting for
more entropy, but no entropy is forthcoming because the system is
entirely idle just waiting for something to happen.
While this was triggered by what is arguably a user space bug with
GDM/gnome-session asking for secure randomness during early boot, when
they didn't even need any such truly secure thing, the issue ends up
being that our "getrandom()" interface is prone to that kind of
confusion, because people don't think very hard about whether they want
to block for sufficient amounts of entropy.
The approach here-in is to decide to not just passively wait for entropy
to happen, but to start actively collecting it if it is missing. This
is not necessarily always possible, but if the architecture has a CPU
cycle counter, there is a fair amount of noise in the exact timings of
reasonably complex loads.
We may end up tweaking the load and the entropy estimates, but this
should be at least a reasonable starting point.
So once this kernel is available in your distribution, you should be safe from entropy starvation at boot on any platform that has hardware timers (I haven't encountered one that does not in the last decade).
Ted Ts'o reviewed the approach and was fine and Ahmed Dawish did some testing of the quality of randomness generated and that seems fine, too.
Updates
14.01.2019
Stefan Fritsch, the Apache2 maintainer in Debian, OpenBSD developer and a former Debian security team member stumbled over the systemd issue preventing Apache libssl to initialize at boot in a Debian bug #916690 - apache2: getrandom call blocks on first startup, systemd kills with timeout.
The bug has been retitled "document getrandom changes causing entropy starvation" hinting at not fixing the underlying issue but documenting it in the Debian Buster release notes.
Unhappy with this "minimal compromise" Stefan wrote a comprehensive summary of the current situation to the Debian-devel mailing list. The discussion spans over December 2018 and January 2019 and mostly iterated what had been written above already. The discussion has - so far - not reached any consensus. There is still the "systemd stance" (not our problem, fix the daemons) and the "ssh/apache stance" (fix systemd, credit entropy).
The "document in release notes" minimal compromise was brought up again and Stefan warned of the problems this would create for Buster users:
> I'd prefer having this documented in the release notes:
> https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=916690
> with possible solutions like installing haveged, configuring virtio-rng,
> etc. depending on the situation.
That would be an extremely user-unfriendly "solution" and would lead to
countless hours of debugging and useless bug reports.
This is exactly why I wrote this blog entry and keep it updated. We need to either fix this or tell everybody we can reach before upgrading to Buster. Otherwise this will lead to huge amounts of systems dead on the network after what looked like a successful upgrade.
Some interesting tidbits were mentioned within the thread:
Raphael Hertzog fixed the issue for Kali Linux by installing haveged by default. Michael Prokop did the same for the grml distribution within its December 2018 release.
Ben Hutchings pointed to an interesting thread on the debian-release mailing list he kicked off in May 2018. Multiple people summarized the options and the fact that there is no "general solution that is both correct and easy" at the time.
Sam Hartman identified Debian Buster VMs running under VMware as an issue, because that supervisor does not provide virtio-rng. So Debian VMs wouldn't boot into ssh availability within a reasonable time. This is an issue for real world use cases albeit running a proprietary product as the supervisor.
16.01.2019
Daniel Kahn Gillmor wrote in to explain a risk for VMs starting right after the boot of the host OS:
If that pool is used by the guest to generate long-term secrets because it appears to be well-initialized, that could be a serious problem.
(e.g. "Mining your P's and Q's" by Heninger et al -- https://factorable.net/weakkeys12.extended.pdf)
I've just opened https://bugs.launchpad.net/qemu/+bug/1811758 to report a way to improve that situation in qemu by default.
So ... make sure that your host OS has access to a hardware random number generator or at least carries over its random seed properly across reboots. You could also delay VM starts until the crng on the host Linux is fully initialized (random: crng init done).
Otherwise your VMs may get insufficiently generated pseudo-random numbers and won't even know.
12.03.2019
Stefan Fritsch revived the thread on debian-devel again and got a few more interesting tidbits out of the developer community:
Ben Hutchings has enabled CONFIG_RANDOM_TRUST_CPU for Debian kernels from 4.19.20-1 so the problem is somewhat contained for recent CPU AMD64 systems (RDRAND capable) in Buster.
Thorsten Glaser developed early-rng-init-tools which combine a few options to try and get entropy carried across boot and generated early during boot. He received some scrutiny as can be expected but none that would discourage me from using it. He explains that this is for early boot and thus has initrd integration. It complements safer randomness sources or haveged.
16.04.2019
The Debian installer for Buster is running into the same problem now as indicated in the release notes for RC1.
Bug #923675 has details. Essentially choose-mirror waits serveral minutes for entropy when used with https mirrors.
08.05.2019
The RDRAND use introduced in systemd to bypass the kernel random number generator during boot falls for a AMD pre-Ryzen bug as RDRAND on these systems doesn't return random data after a suspend / resume cycle. Added an update note to the systemd section above.
03.06.2019
Bastian Blank reports the issue is affecting Debian cloud images now as well as cloud-init generates ssh keys during boot.
10.07.2019
Added the update of jitterentropy_rng to a version based on upstream v2.1.2 into the Jitterentropy section above.
16.09.2019
The Linux Kernel Mailing List (LKML) is re-iterating the entropy starvation issue and the un-willingness of systemd to fix its usage of randomness in early boot. Ahmed S. Darwish has reported the issue leading to ext4 reproducibly blocking boot with Kernel 5.3-r8. There are a few patches floated and the whole discussion it worth reading albeit non-conclusive as of now.
Ted Ts'o says "I really very strongly believe that the idea of making getrandom(2) non-blocking and to blindly assume that we can load up the buffer with 'best efforts' randomness to be a terrible, terrible idea that is going to cause major security problems that we will potentially regret very badly. Linus Torvalds believes I am an incompetent systems designer." in this email.
In case you needed a teaser to really start reading the thread! Linus Torvalds also mentions the issue (and a primer on what "never break userspace" means) in the Linux kernel 5.3 release notes.
18.09.2019
... and Martin Steigerwald kindly noticed that I update this blog post with the relevant discussions I come across as this entropy starvation mess continues to haunt us.
25.11.2019
Added the "Linus to the rescue" section after the Linux kernel 5.4 has been released.
02.04.2020
I ran into the same issue on a Gentoo system today. Luckily OpenRC handeled this gracefully but it delayed booting:
syslog-ng actually hangs the boot for some time ... waiting for entropy. Argh.
The Gentoo forums thread on the topic clearly listed the options:
- Make syslog-ng depend on haveged by adding
rc_syslog_ng_need="haveged" to /etc/rc.conf (and obviously having haveged installed)
- Re-compiling the kernel with
CONFIG_RANDOM_TRUST_CPU=y where that is an option

")



 Edition\" this time")







")
 again")





")
